~/abhipraya
[S3, W2] PPL: Four Reviews, Four Real Bugs Caught
What I Worked On
Six substantive reviews this week, plus several smaller ones. I want to walk through the reviews where the bugs caught were not the kind you spot by reading the diff line-by-line. Each one needed either running the code, decoding artifacts, or thinking about a layer the author had not stress-tested. Across the six MRs I posted 19 P0, 36 P1, 20 P2, and 8 P3 findings, all as discussion threads (not plain comments).
Review !220: A 1-Hour Signed URL Persisted Forever
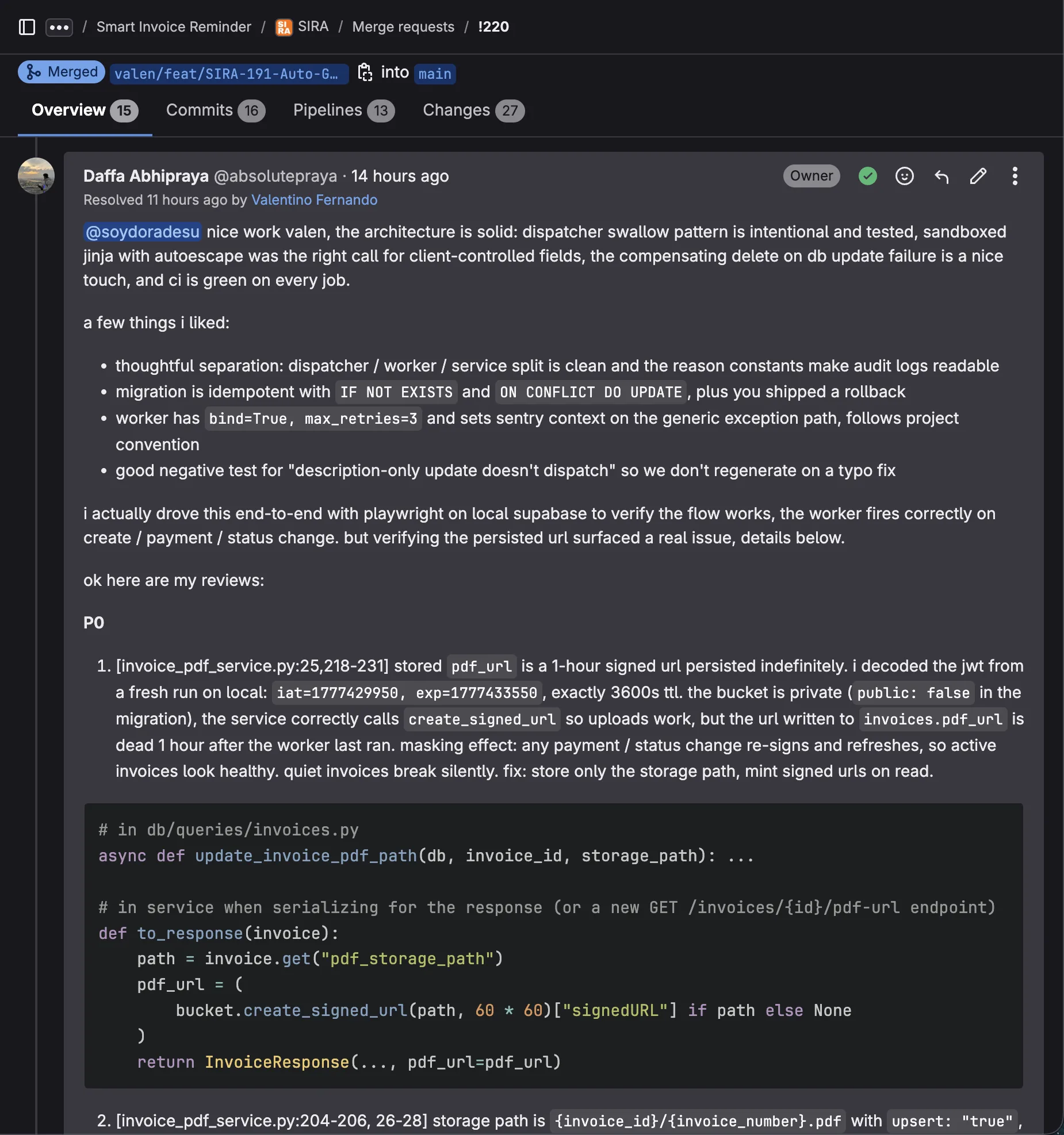
MR !220 (auto-generate PDF on invoice creation, by @soydoradesu) added a Celery worker that renders an invoice PDF, uploads it to a private Supabase Storage bucket, and persists the URL to invoices.pdf_url. The reviewer-friendly path is to read the diff, see create_signed_url(...), see the bucket marked public: false, and approve. That would have shipped a real bug.
I drove the flow end-to-end with Playwright on local Supabase. Created a client, created an invoice, watched the worker fire, opened the database row, copied the pdf_url value, and decoded the JWT in its query string:
import base64, json
url = "https://...storage/v1/object/sign/invoices/...?token=eyJ..."
token = url.split("token=")[1].split("&")[0]
payload = json.loads(base64.urlsafe_b64decode(token.split(".")[1] + "=="))
print(payload)
# {'iat': 1777429950, 'exp': 1777433550, ...}
print(payload['exp'] - payload['iat'])
# 3600
Exactly 3600 seconds: a 1-hour TTL. The bucket is private, so the URL stops working at the 1-hour mark. The masking effect is what made this dangerous: any payment recorded or status change re-runs the worker (upsert: True), which mints a fresh URL. Active invoices look healthy. Quiet invoices break silently after an hour and never recover.
The fix in the review:
# Don't persist the signed URL. Persist the storage path, mint URLs on read.
async def update_invoice_pdf_path(db, invoice_id, storage_path): ...
def to_response(invoice):
path = invoice.get("pdf_storage_path")
pdf_url = (
bucket.create_signed_url(path, 60 * 60)["signedURL"] if path else None
)
return InvoiceResponse(..., pdf_url=pdf_url)
A second P0 came from looking at the storage path: {invoice_id}/{invoice_number}.pdf with upsert=True. Every regenerate overwrites in place. If a recipient was emailed the prior URL and we regen on a status change, the old URL now points at a different document. That is an audit smell for invoices, which should be stable artifacts. Fix: include a version number in the path and drop upsert.
The reviewer takeaway here is that artifacts that look like data must be inspected as artifacts. The JWT in the URL was the actual evidence of the bug. Reading the source code would never have surfaced the TTL because the source code is correct (it asks for a 1-hour signed URL, and that’s exactly what it gets); the bug is the mismatch between the URL’s TTL and the row’s lifetime. You only see that mismatch by treating the URL as a thing to inspect, not just a string to read.
Review !217: Three Layers of Sentry Misconfiguration
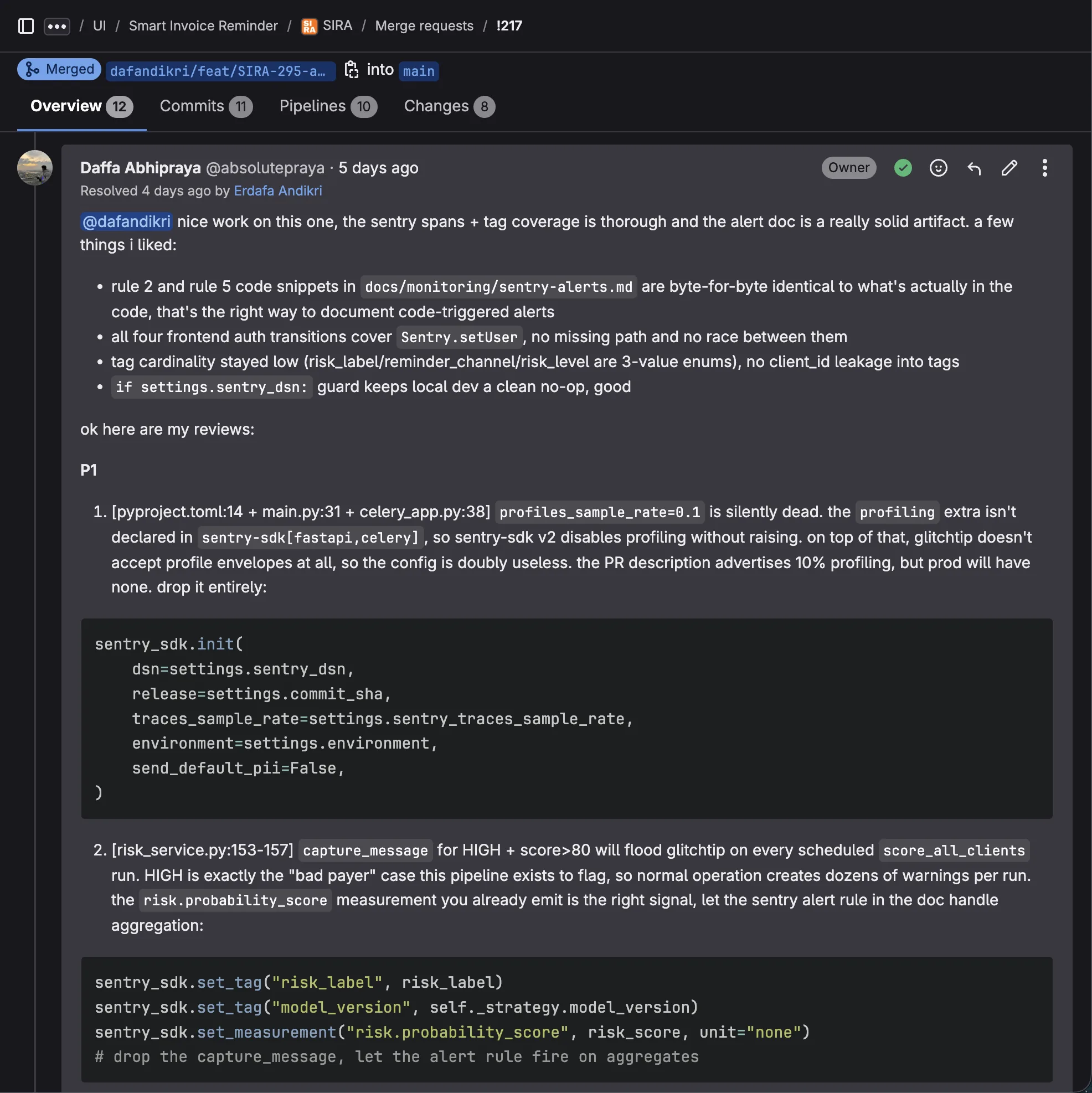
MR !217 (advanced platform monitoring, by @dafandikri) added Sentry user identity, ML instrumentation, and four alert rules. The diff was large, well-tested, and looked correct on first reading. Three issues surfaced when I traced the actual SDK behavior.
P1 #1: dead profiling config. The MR description advertises 10% profiling. The code sets profiles_sample_rate=0.1 in sentry_sdk.init. But the profiling extra is not declared in the sentry-sdk[fastapi,celery] install, so sentry-sdk v2 silently disables profiling without raising. On top of that, GlitchTip (our self-hosted Sentry) does not accept profile envelopes at all. The config is doubly useless: prod will have no profiling data despite the parameter being set. Fix: drop the parameter entirely so the description is accurate.
P1 #2: capture_message floods on every scoring run. The risk service calls sentry_sdk.capture_message(...) whenever a client gets HIGH risk + score>80. HIGH is exactly the “bad payer” case the pipeline exists to flag. Normal operation creates dozens of warnings per scheduled run of score_all_clients. The risk.probability_score measurement they already emit is the right signal: let the alert rule in the doc handle aggregation, drop the per-event capture.
P1 #3: tag bleeding across iterations. sentry_sdk.set_tag writes to the shared isolation scope. score_all_clients calls score_client in a tight loop. Each iteration overwrites the previous client’s tags, but spans and breadcrumbs from earlier in the same iteration (like the db.query span before tags are set) carry the previous client’s risk_label. Fix: wrap each per-client run in sentry_sdk.isolation_scope():
async def score_client(self, client_id: str) -> RiskScoreResult:
with sentry_sdk.isolation_scope():
# ...spans, db calls...
sentry_sdk.set_tag("risk_label", risk_label)
sentry_sdk.set_tag("model_version", self._strategy.model_version)
sentry_sdk.set_measurement("risk.probability_score", risk_score)
This one is the kind of bug that does not crash anything, it just silently corrupts your monitoring data so all your dashboards lie. Catching it in review beats catching it three months later when you cannot trust the numbers.
Review !218: Public PDFs Containing Regulated PII
MR !218 (Invoice PDF Generator Service, by @soydoradesu) is the precursor to !220. The PDF service uses bucket.get_public_url() and never marks the bucket private. The PDFs embed NPWP (Indonesian tax ID, regulated PII) plus invoice amounts. Invoice UUIDs are guessable.
This is a P0 directly: any unauthenticated person who can guess invoice UUIDs can pull tax IDs. The fix is two changes (private bucket, signed URL with TTL), and they need to be in the same MR because the failure mode is “ship the public path, forget to come back”. Caught in review and required before merge.
A secondary P0 in the same MR: bucket.upload(...) return value discarded. storage3 does not always raise on failure (quota, RLS, mime type, size limits). A failed upload still produces a URL that gets persisted and served as a broken link. The fix:
response = bucket.upload(storage_path, pdf_bytes, file_options=_PDF_FILE_OPTIONS)
if getattr(response, "error", None) or not getattr(response, "path", None):
raise RuntimeError(f"PDF upload failed for {storage_path}: {response}")
Review !203: An RLS Policy That Looks Strict But Is Advisory
MR !203 (BE Payment Proof Storage Setup, by @fadhlurohmandzaki) added a Supabase Storage bucket with row-level-security policies on INSERT, SELECT, and DELETE. The policies look airtight: they check payment_versions.created_by against auth.uid(), so only the user who created the payment can manipulate proofs.
The catch: our API uploads via the service-role client, not the user’s JWT. service-role bypasses RLS entirely. The policies are effectively advisory for the current upload path; the actual enforcement is happening in PaymentService.upload_proof’s ownership check, not the database.
This is not a security hole in the immediate sense (the service-layer check still works), but it is a lie in the code: anyone reading the migration thinks the database is enforcing access. When somebody later switches the upload path to use the user’s JWT (a reasonable refactor), they will assume RLS is already wired and skip adding the service-layer check. The fix is a 4-line comment in the migration:
-- NOTE: API uploads via service_role so these policies are advisory.
-- Enforcement happens in PaymentService.upload_proof ownership check.
-- If switching to user-JWT uploads, verify policies still match needs.
A second finding in the same MR was the ownership query itself. is_payment_owned_by_user matched any payment_versions.created_by, but payment_versions is “who edited”, not “who owns”. Any admin who ever touched the payment becomes a permanent owner. Scoping the query to version_number = 1 (the original creator) fixed it.
Review !216: Committed Fixtures, Lowered Coverage Threshold, Other Repo-Wide Misses
MR !216 (Nielsen heuristics UI improvements, by @dafandikri) was a large UI-quality MR with 56 discussion notes by the time I was done. The diff itself was mostly genuine UI work, but the surrounding scaffolding had several issues that would have shipped permanent damage to the repo. Six P0s, twelve P1s, seven P2s, four P3s. The most serious ones were not in the source code at all; they were in what got committed alongside it.
P0: test_db.py accidentally committed to the repo. A local test database snapshot file (binary) had been staged and pushed. That kind of artifact pollutes the repo permanently because git history retains it forever, even after deletion. The fix was a git revert plus a .gitignore entry covering the pattern.
P0: .gitlab-ci.yml lowered the coverage threshold. The CI config in the diff included coverage_threshold: 60 where the project standard had been 80. Once that lands on main, every subsequent MR has the lower bar. This is the kind of “ratchet down” change that tends to compound: nobody notices the standard moved because tooling still says “passing”.
P0: .hypothesis/, .opencode/, .serena/ artifact directories committed. Generated artifacts from local tooling. Same class of problem as test_db.py: bloats the repo, irrelevant to other developers, leaks information about the author’s local setup.
P0: InvoiceForm submit firing despite visible validation errors. A real user-facing bug: the form rendered red error states on the inputs but the submit button still proceeded with the request. Fix was to gate handleSubmit on formState.isValid.
P0: empty .catch(() => {}) swallowing refetch failures across 4 components. When a TanStack Query refetch fails after a mutation, the silent catch hides the error from both the user and Sentry. Fix: re-throw or report.
The takeaway from this review: the most dangerous P0s in a UI MR were not UI bugs. They were repo-hygiene and coverage-policy regressions that the diff snuck in. Future reviewers should explicitly check the file list, not just the diff, for any MR larger than ~10 files.
Review !213: Unbounded Queries Will Silently Lie
MR !213 (AR analytics dashboard, by @dafandikri) was the largest review of the week: 9 P0, 19 P1, 13 P2, 4 P3, total 45 findings across 48 discussion threads. The dashboard touched four Linear tickets (SIRA-172/173/174/175) and pulled metrics from six different tables. The size alone meant something would slip; what surprised me was how many of the issues were variations on the same theme.
P0: unbounded Supabase queries everywhere. Supabase’s PostgREST silently caps query results at 1000 rows by default. The dashboard’s “total invoices” metric used .select("*") with no .range() or .limit(). The moment the project crosses 1000 invoices in production, every metric (totals, aging buckets, risk distribution) starts to silently undercount. Catastrophic and invisible. Fix: explicit .range(0, count_required - 1) or use .select("*", count="exact", head=True) for counts that don’t need the rows.
P0: full-table fetches on the frontend replacing what should have been server-side LIMIT 5. The “Top 5 overdue clients” widget pulled the entire clients table, then sliced it client-side. Same problem at a different layer: works fine for tens of clients, breaks invisibly at scale, and wastes bandwidth even when it works.
P0: swallowed query errors hiding 500s as empty states. Several queries had error handlers that returned [] on failure. The widgets then rendered “No data” UI. A backend 500 looked identical to “no data exists yet”. The dashboard would lie quietly under partial outage. Fix: distinguish empty data from query failure, render an explicit error state.
P0: stringly-typed aging buckets. Aging buckets (“0-30 days”, “31-60 days”, “61-90 days”, “90+ days”) were strings in the API response, the frontend type definitions, and the chart axis. Renaming a bucket label requires touching all three places, and the compiler won’t catch a mismatch. Fix: enum at the schema level, derived strings only in display code.
P0: missing integration test on /dashboard/analytics. With a feature this central to the product (the AR dashboard is the primary product surface), the absence of an end-to-end integration test was a P0 by itself. The unit tests covered each query in isolation, but no test verified that the full dashboard rendered against a real Supabase with seeded data.
The takeaway from this review: the dangerous bugs in a data-heavy MR are about scale, not logic. The queries were correct for any test data set. They became wrong only at production scale. Reviews of dashboard/metrics MRs need to ask “what happens at 10x, 100x, 1000x the test data” for every query, not just the ones with explicit LIMIT.
How I Approach Reviews
A few habits I have settled into this sprint:
- Run the code if I can. The !220 JWT bug was only visible from a real run. Playwright on local Supabase took 5 minutes to set up and surfaced something the diff hid.
- Open every diff against the runtime, not the spec. !217’s profiling bug was about what the SDK actually does, not what the parameter promises.
- Look at boundaries, not lines. RLS policy + service-role client (!203), public bucket + private content (!218), 1-hour URL + indefinite row (!220). The bugs lived at boundaries between layers, not inside any single file.
- Check the file list, not just the diff. !216’s most damaging P0s (committed
test_db.py, lowered coverage threshold, artifact directories) all lived in files that a line-by-line code review would not have flagged. - Ask “what happens at 1000x the test data”. !213’s unbounded-query P0s were correct on a 50-row test database and broken on a 5000-row production one.
- Always write a positives section first. Every review opens with what the author got right. The dispatcher pattern in !220 is genuinely clean. The frontend auth coverage in !217 is thorough. Calling those out is honest and changes how the rest of the review lands.
Total this week across six substantive reviews: 19 P0, 36 P1, 20 P2, 8 P3 — 83 findings across 6 MRs, all posted as threaded discussions, every P0 either resolved by the author before merge or accepted with a follow-up ticket. Nobody pushed back on a single P0 because the evidence was always concrete: the JWT, the SDK behavior, the missing private flag, the service-role bypass, the committed fixture file, the unbounded query.
Evidence
- MR !213 SIRA-172/173/174/175 AR analytics dashboard — 9 P0, 19 P1, 13 P2, 4 P3 (45 total findings)
- MR !216 SIRA-294 Nielsen heuristics UI improvements — 6 P0, 12 P1, 7 P2, 4 P3 (29 total findings)
- MR !220 SIRA-191 Auto-generate PDF on Invoice Creation
- MR !217 SIRA-295 advanced platform monitoring
- MR !218 SIRA-190 Invoice PDF Generator Service
- MR !203 SIRA-193 BE Payment Proof Storage Setup
- Also reviewed: !224 Client Analytics Page, !229 strftime fix, !219 Duplicate Client Detect, !215 Boneyard skeletons (12 commits contributed during review)