~/abhipraya
[S2, W3] PPL: Quality as a Feedback Loop
What I Worked On
Two weeks of quality infrastructure: wiring in the tools that measure test quality (week 1), then shortening the feedback loop so that signal actually influences the code being written (week 2). Starting state: 91% line coverage, no mutation testing, integration test coverage missing from SonarQube. Ending state: combined unit + integration coverage in SonarQube, mutmut + Stryker running per-MR with results in the CI comment, API mutation score 80.3%.
The arc is not “we added more tools.” It is “we made the existing signal visible where developers actually look.”
Week 1: The Coverage Gap — Integration Tests Missing From SonarQube
Before MR !149, SonarQube coverage was generated only from unit test runs. Integration tests (which hit real Supabase and verify actual state transitions) executed in a separate CI job but their coverage was never merged into the SonarQube report. A route handler tested exclusively via integration tests showed 0% coverage in SonarQube even if it was fully tested.
MR !149 merged coverage files from both jobs before uploading:
sonar-scan:
script:
- cd apps/api
- uv run coverage combine .coverage.unit .coverage.integration || true
- uv run coverage xml -o coverage.xml
- sonar-scanner ...
The combine step merges multiple .coverage files. || true prevents failure when the integration coverage file does not exist (a branch without integration test changes still works).
Week 1: Mutation Testing as a Second Quality Dimension
Coverage tells you a test executed a line. Mutation testing tells you a test would have caught a bug on that line. These are different questions, and a test suite can ace the first while failing the second.
Week 1 wired both mutation tools into CI:
- Python: mutmut against
src/app/services/(business logic). Router mutations excluded because they would only test FastAPI internals, not our code. - TypeScript: Stryker against
src/lib/(shared utilities). API client, Supabase client, auth context excluded — they are integration points that can’t be tested under mutation conditions.
Stryker thresholds enforce a floor:
"thresholds": {
"high": 80,
"low": 60,
"break": 50
}
Mutation score below 50% fails the CI job. The high: 80 is the green bar we aim at.
Week 1: Disk Management Because OOM Hides Quality Failures
MR !147 added a disk cleanup step at the start of every pipeline. Not cosmetic.
The Nashta VM has 48 GB of disk shared across Docker images, build artifacts, and the CI runner. After days of mutation testing runs each pulling Docker images and generating HTML reports, disk usage grew to the point where jobs failed mid-execution with “no space left on device.”
These failures were invisible in quality terms. A pipeline stage failing due to disk exhaustion looks identical to one failing due to bad code. SonarQube uploads don’t complete, quality gate results stay stale, CI comments show “failed” with no useful signal.
before_script:
- docker system prune -f --volumes 2>/dev/null || true
- docker image prune -f 2>/dev/null || true
The || true keeps the prune from failing the pipeline if Docker is unreachable in that runner context. Cheap defense, high value.
Week 2: Moving Mutation Testing Left
Week 1 got mutation testing working on main. The problem: quality regressions only surfaced AFTER merge. Developers writing the PR had no mutation signal until their change was already in.
Week 2’s goal: auto-run on every MR pipeline, post the result as a CI comment, close the loop before merge.
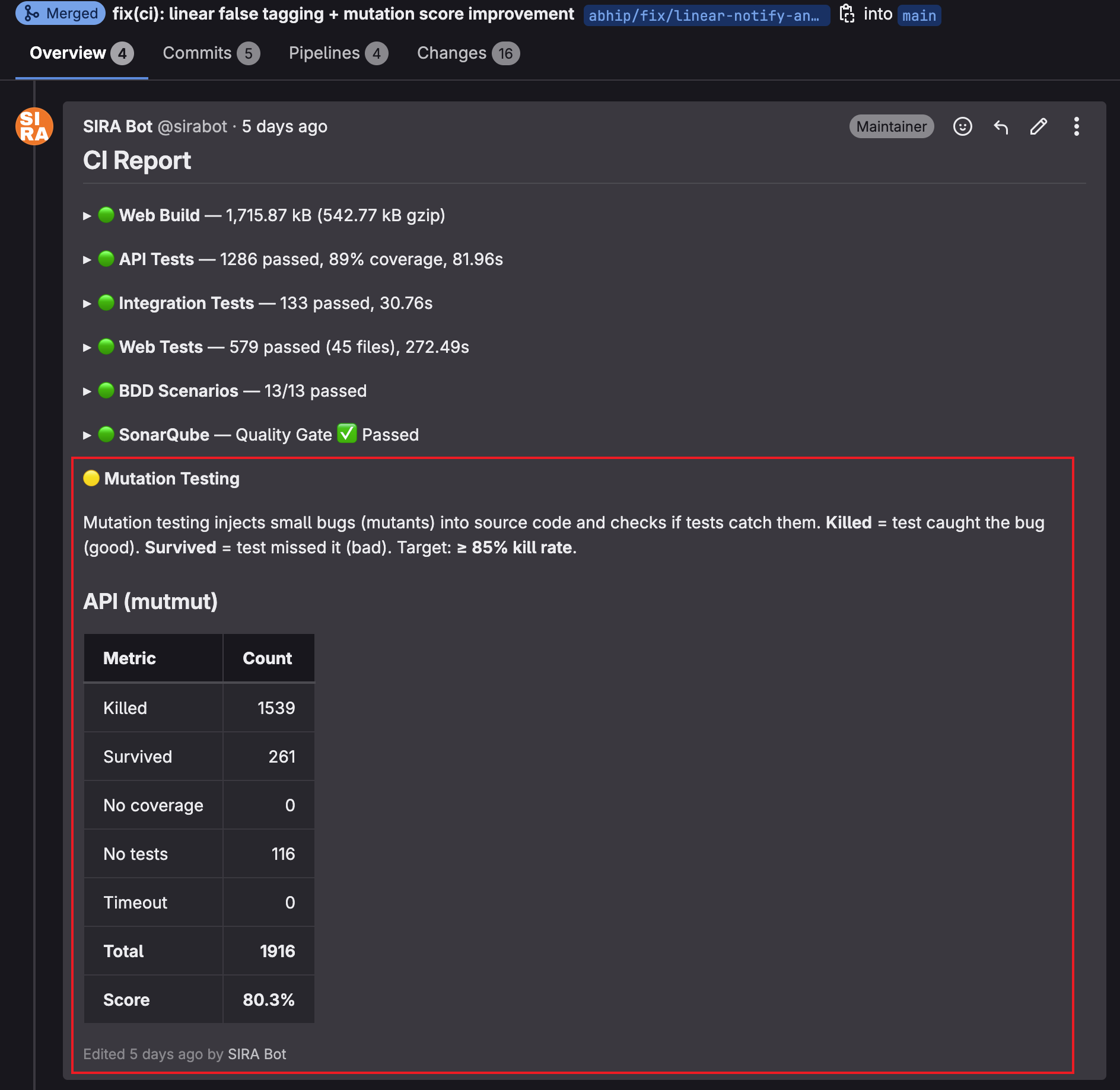
MR !183 added ci-report.sh mutation as a new subcommand. Every MR pipeline now includes a block like:
## 🧬 Mutation Testing
Mutation testing modifies source code in small ways ("mutants") and runs
the test suite. A mutant "killed" means a test failed, proving the tests
would catch that bug. A "survived" mutant means no test detected the change,
revealing a coverage gap. Target: **85%** killed.
### API (mutmut)
| Metric | Count |
|--------|------:|
| Killed | 1539 |
| Survived | 261 |
| No coverage | 0 |
| No tests | 116 |
| Timeout | 0 |
| Total | 1916 |
| Score | 80.3% |
The explanation text (added in MR !185) exists because “killed/survived” is ambiguous without framing. The four categories distinguish different fixes:
- Killed: tests detected the mutation. Quality win.
- Survived: tests ran but no assertion failed. Coverage gap to fix with a better assertion.
- No coverage: code no test touches. Fix with a basic test first.
- Timeout: mutant caused an infinite loop. Usually config, not quality.
Separating “survived” from “no coverage” matters because the fixes are different. Lumping them (as line coverage does with covered/uncovered) loses that distinction.
Week 2: The 0% Report Bug (MR !184)
After !183 shipped, the first MR pipelines showed mutmut with 0 killed / 0 survived / 500 not checked. Every mutant “not checked.” Score reported: 0%.
The cause: mutmut’s baseline step runs the full test suite against unmutated code. If any test fails, mutmut refuses to proceed — “tests failing on clean code” means mutation results would be noise. In CI, integration tests hit Supabase’s local rate limits (429 Too Many Requests) on parallel runs, pytest failed with network errors, mutmut aborted baseline, every mutant was “not checked.”
The fix was one line in pyproject.toml:
pytest_add_cli_args = [
"-m", "not integration", # ← added this
"--ignore=tests/test_db_schema_and_seed.py",
# ... other ignores
]
Why Integration Tests Should Not Be Mutated
This decision deserves its own paragraph because it is counter-intuitive. Integration tests use the real database. If mutmut mutates InvoiceService.create_invoice and the test runs real_db.table("invoices").select(...).execute(), most mutations will fail the integration test because the DB schema enforces constraints the mutant violates. “More tests killing more mutants” sounds good — but it conflates signals.
Mutation testing asks: “if this line changes, does your test suite catch it?” The goal is finding gaps in unit and service tests where assertions are weak. If an integration test catches every mutation, it tells you the DB schema is enforcing the invariant, not that your tests are. The integration test would pass against real code AND against a broken mutant that happened to produce the same DB state. Signal lost.
So mutmut runs against unit tests only. Integration tests are a separate quality signal, tracked by code coverage, not mutation score.
Week 2: The Stryker Auto-Run Experiment (MR !186 → !187)
Stryker was manual on main because it took 38 minutes. MR !186 tried to make it auto-run on MRs by removing the heaviest config: the @stryker-mutator/typescript-checker plugin.
The plugin runs tsc per mutant, rejecting type-invalid ones before vitest runs. Conceptually nice — saves vitest time. In practice, the plugin doubles Stryker’s runtime (tsc per mutant × 588 mutants), and for our project the savings don’t materialize: vitest already kills type-invalid mutants at runtime (they throw undefined is not a function, test fails, Stryker counts killed). Mutation score was identical with or without the plugin.
// stryker.config.json — removed
"checkers": ["typescript"],
Stryker time dropped from 38 minutes to 28 minutes. Still too slow to block MR merges (most pipelines complete in under 10 minutes). MR !187 walked back auto-run and restored manual invocation:
mutation:typescript:
stage: quality
when: manual
allow_failure: true
The walk-back is the right call but worth naming explicitly. Removing a quality gate from blocking a merge is not a loss if the gate is slower than the merge flow tolerates. A 28-minute check that delays every MR by 28 minutes is more expensive than the bugs it catches. Manual invocation on PRs that matter (pre-release checks, major service refactors) recovers the value without the latency.
The 85% Target
The report’s “Target: 85% killed” guideline came from measuring the existing suite’s ceiling after a reasonable strengthening pass:
- Pre-round-2 mutation testing: ~66% for API
- After round 2 (200+ tests): ~75%
- After round 3 (per-method survivor targeting): 80.3%
85% is the next credible step. Above 90% requires chasing low-value mutations (log message strings, defensive unreachable branches, config defaults) that add test maintenance burden without catching real bugs. 85% is where cost/benefit inflects.
Stryker (Web) sits around 60% because frontend lib code has different characteristics: lots of pure data transformations where a single test kills many mutants, but also React component utility code where mutation coverage is inherently harder (rendering-dependent behavior).
Before vs. After Across Both Weeks
| Metric | Start of week 1 | End of week 2 |
|---|---|---|
| SonarQube coverage source | Unit tests only | Unit + integration combined |
| Mutation testing | Not in CI | mutmut (Python) + Stryker (TypeScript) per-MR |
| Mutation feedback cadence | N/A | Every MR comment |
| Disk management | Manual | Auto-prune at pipeline start |
| API mutation score | ~66% | 80.3% (1539/1916 killed) |
| Stryker mutation score | N/A | ~60% manual |
| Quality gate dimensions | Coverage only | Coverage + mutation score |
The structural shift is from “measure once on main” to “every MR has the number in its comment.” The score itself moving from 66% to 80% is a direct consequence of that feedback loop being closed.
Evidence
- MR !149 — chore(ci): integration test coverage in SonarQube
- MR !147 — chore(ci): disk cleanup before every pipeline
- MR !144 — SIRA-242: integration test infrastructure
- MR !145, !146, !148, !152, !153, !156, !158, !159 — week 1 mutation testing CI series
- MR !183 — chore(ci): mutation testing on MR pipelines + report comments
- MR !184 — fix(ci): mutmut 0% score (integration test exclusion)
- MR !185 — fix(ci): mutation report explanation + 400+ strengthened tests
- MR !186 → !187 — Stryker auto-run experiment and walk-back
- Source:
scripts/ci-report.sh(mutation subcommand),apps/api/pyproject.toml,apps/web/stryker.config.json,.gitlab-ci.yml