~/abhipraya
PPL: Optimizing Test Design Beyond Line Coverage
Line coverage is the metric most teams report to prove their tests work. It is also the metric most likely to mislead them. In this blog I walk through three complementary techniques we applied to a FastAPI + React monorepo to optimize test design past the “coverage looks fine” plateau: mutation testing to measure assertion strength, property-based testing as a practical form of Input Space Partitioning, and branch coverage enforced via a CI quality gate to pin down control-flow discipline. Each technique answers a question that line coverage cannot, and the combination is what turns “my tests execute the code” into “my tests actually catch regressions.”
Note: Our project is hosted on an internal GitLab instance, so we use the term MR (Merge Request) throughout this blog. If you’re coming from GitHub, MRs are the equivalent of Pull Requests (PRs).
Why Line Coverage Is a Lagging Indicator
Line coverage answers a shallow question: did my tests execute this line? That is easy for the tool to measure and easy for the team to report. It is also easy to satisfy without actually testing anything.
Consider a test that calls invoice_service.create() and asserts result is not None. The line is covered. Replace the implementation with return MagicMock() and the test still passes. 100% line coverage, zero real assertions.
This is not a hypothetical. On our backend, we had 91% line coverage on the services layer and 1099 passing tests before we introduced mutation testing. The first mutation run showed entire service files with mutation scores in the 40-60% range. The tests were executing the lines; they just were not asserting what the lines produced.
The three techniques below address three different failure modes of line-coverage-only testing:
| Technique | What line coverage misses | What this catches |
|---|---|---|
| Mutation testing | Weak assertions that pass against wrong outputs | Tests that claim to cover a line but don’t actually check its behavior |
| Input Space Partitioning (property-based) | Edge cases the test author did not think of | Unicode, empty strings, boundary numbers, date transitions, None flowing through unchecked |
| Branch coverage | Untaken conditional branches on “covered” lines | if/else branches where only one side is ever tested, even when the line is 100% covered |
This taxonomy is not mine. It maps directly onto Ammann and Offutt’s Introduction to Software Testing (2nd ed., Cambridge, 2017), the textbook that defines each of these criteria formally. The academic framing is useful because it gives each technique a clear target and a clear limit.
Technique 1: Mutation Testing as Assertion-Strength Audit
Mutation testing asks the question line coverage cannot: if this line changed, would my tests notice?
The tool modifies source code in small, plausible ways called mutants: flipping > to >=, replacing == 200 with != 200, changing a string constant, deleting a function call. It then runs the test suite against each mutated version. If no test fails, the mutant survived, which proves a real bug of that shape would have shipped. The mutation score is the percentage of mutants killed.
Academically this is a form of fault-based testing: the theory (Ammann & Offutt, Chapter 9) is that most real bugs are syntactically similar to these small mutations, so a test suite that kills most mutants will also catch most real bugs. Empirical studies back this up — the correlation between mutation score and real-bug detection is substantially tighter than the correlation between line coverage and real-bug detection.
Tooling Choice
Two tools, one per language:
- mutmut for Python (
apps/api). AST-based mutation engine, integrates cleanly with pytest. - Stryker for TypeScript (
apps/web). Ships with a Vitest runner and a TypeScript checker that pre-filters mutants that would fail type checking.
Both report the same output shape (killed, survived, timeout, no-coverage) so one mental model works across both stacks.
Scoping: Where to Run Mutations
The interesting configuration decision is where to mutate. Running mutation on an entire codebase is prohibitively expensive (easily hours per run) and produces noise. We scoped aggressively:
# apps/api/pyproject.toml
[tool.mutmut]
paths_to_mutate = ["src/app/services/"]
tests_dir = ["tests/"]
pytest_add_cli_args = [
"-m", "not integration",
"--ignore=tests/test_db_schema_and_seed.py",
"--ignore=tests/test_schemathesis.py",
"-p", "no:randomly",
]
// apps/web/stryker.config.json
{
"mutate": [
"src/lib/**/*.ts",
"!src/lib/api.ts",
"!src/lib/supabase.ts",
"!src/lib/auth-context.tsx",
"!src/lib/query-client.ts"
],
"thresholds": { "high": 80, "low": 60, "break": 50 }
}
The two scoping decisions that matter most:
- Mutate the layer where bugs live, not the glue. Backend routers are thin FastAPI delegation; mutating them only tests the framework, not our logic. Frontend wrappers around Supabase and the API client are similarly glue. We mutate
services/(business logic) andlib/(shared utilities), which is where real reasoning happens. - Exclude tests whose failure is ambiguous under mutation. Integration tests that hit a real database fail for a thousand reasons unrelated to the mutant (network hiccup, transaction isolation, seed data conflict). A mutant failing under an integration test is a low-quality signal. Unit tests with deterministic mocks give a high-quality kill/survive signal.
The Stryker break: 50 threshold is load-bearing: it fails the CI job if mutation score drops below 50%. high: 80 is the green bar the team targets. Without the break, nothing stops someone from merging a change that adds code without adding assertions.
What the First Run Revealed
The initial mutmut run on src/app/services/ scored in the high 60s. Several individual services scored as low as 45%. The gap was almost entirely in assertion strength. Tests were written like:
# Weak assertion — passes against many wrong implementations
result = await service.create_invoice(data)
assert result is not None
assert result.id # just truthy
Mutmut happily produced mutants that returned None, empty objects, or wrong-but-structurally-valid responses, and the tests passed against all of them.
Round 2 and Round 3: Survivor-Driven Test Writing
Surviving mutants can be read as a spec: each one describes behavior the code has that the tests do not verify. Writing tests against survivors is a structured form of TDD where the “failing test” is defined for you:
| TDD step | Mutation-killing equivalent |
|---|---|
| Write a failing test | Pick a surviving mutant — that is the failing test, expressed as code the tests cannot distinguish from the real implementation |
| Make it pass | Write a test whose assertions kill the mutant (and by construction, pass on the real code) |
| Refactor | Re-run mutmut. Confirm new survivors, iterate |
A concrete survivor from EmailService.send_email:
src/app/services/email_service.py:send_email__mutmut_12 survived
Mutant: self.resend_client.emails.send({...}) → None
The mutant replaced the Resend API call with None. Nothing errored. No test asserted what send_email actually returned when the call succeeded. The kill:
def test_send_email_returns_provider_message_id() -> None:
mock_client = MagicMock()
mock_client.emails.send.return_value = {"id": "res_abc123"}
service = EmailService(resend_client=mock_client)
result = service.send_email(
to="test@example.com",
subject="test",
html_body="<p>hi</p>",
)
assert result.success is True
assert result.message_id == "res_abc123"
mock_client.emails.send.assert_called_once()
Three distinct assertions killing three distinct mutation classes: success is True kills mutants returning success=False, message_id == "res_abc123" kills mutants returning None or a hardcoded constant, assert_called_once() kills mutants that skip the Resend call entirely. Each assertion is load-bearing.
Some survivors require integration tests to kill because the behavior under mutation depends on actual database semantics. Consider ClientService.search using ilike for case-insensitive matching. Mutmut changed it to like (case-sensitive) and no unit test noticed — mocked DB clients accept both silently. The kill:
async def test_search_is_case_insensitive(real_db: Client) -> None:
_seed_client(real_db, company_name="Telkom Indonesia")
service = ClientService(real_db)
results_lower = await service.search("telkom")
results_upper = await service.search("TELKOM")
results_mixed = await service.search("TeLkOm")
assert len(results_lower) == 1
assert len(results_upper) == 1
assert len(results_mixed) == 1
This test hits a real Supabase instance. ilike vs like is PostgREST behavior; a mocked DB would accept either silently. Mutation testing told us exactly where our unit tests were insufficient and where we needed integration tests to close the loop.
Measurable Impact
Two rounds of mutation-driven test writing landed over two weeks (~400 new tests across both rounds):
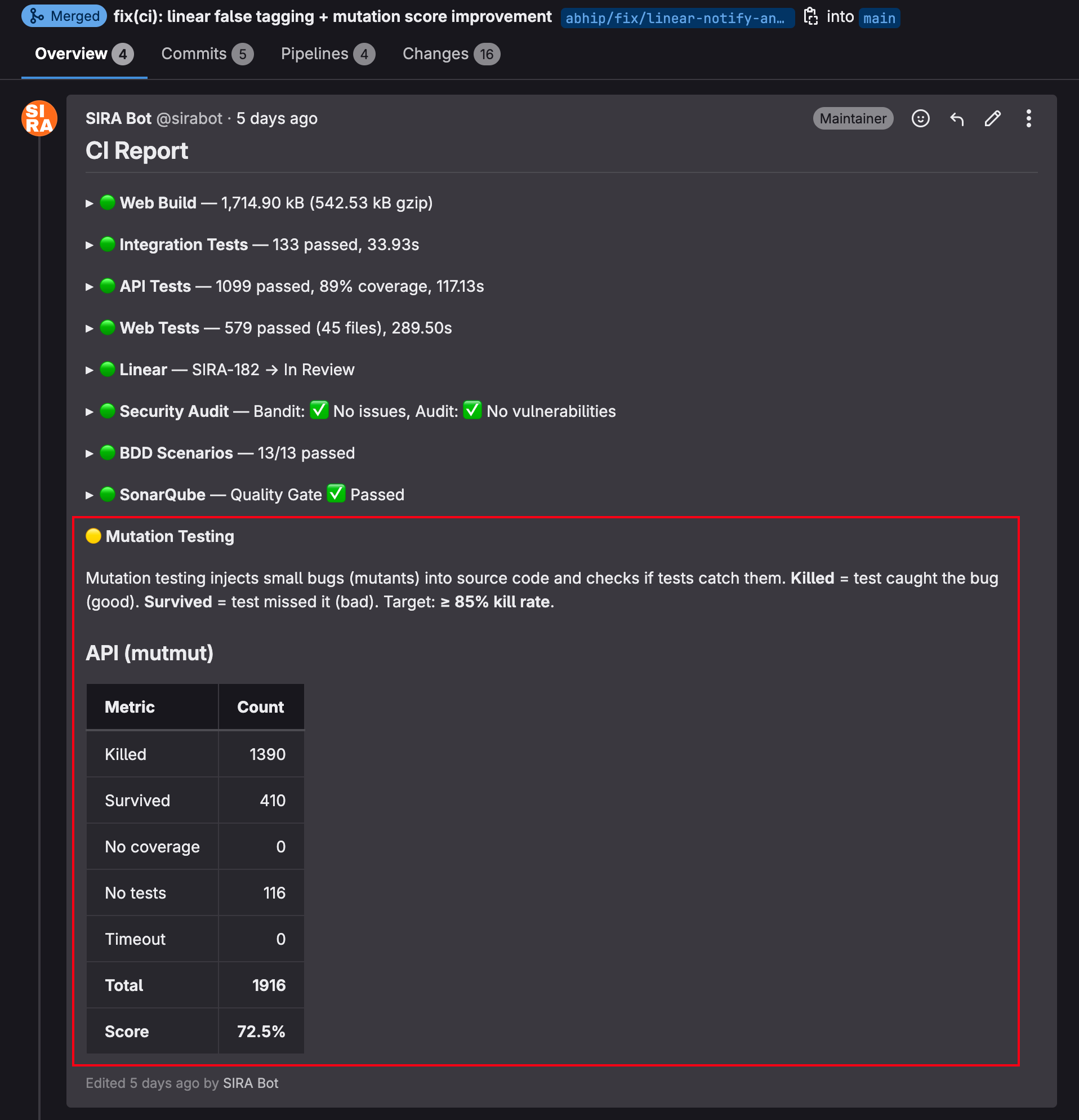
After round 3:
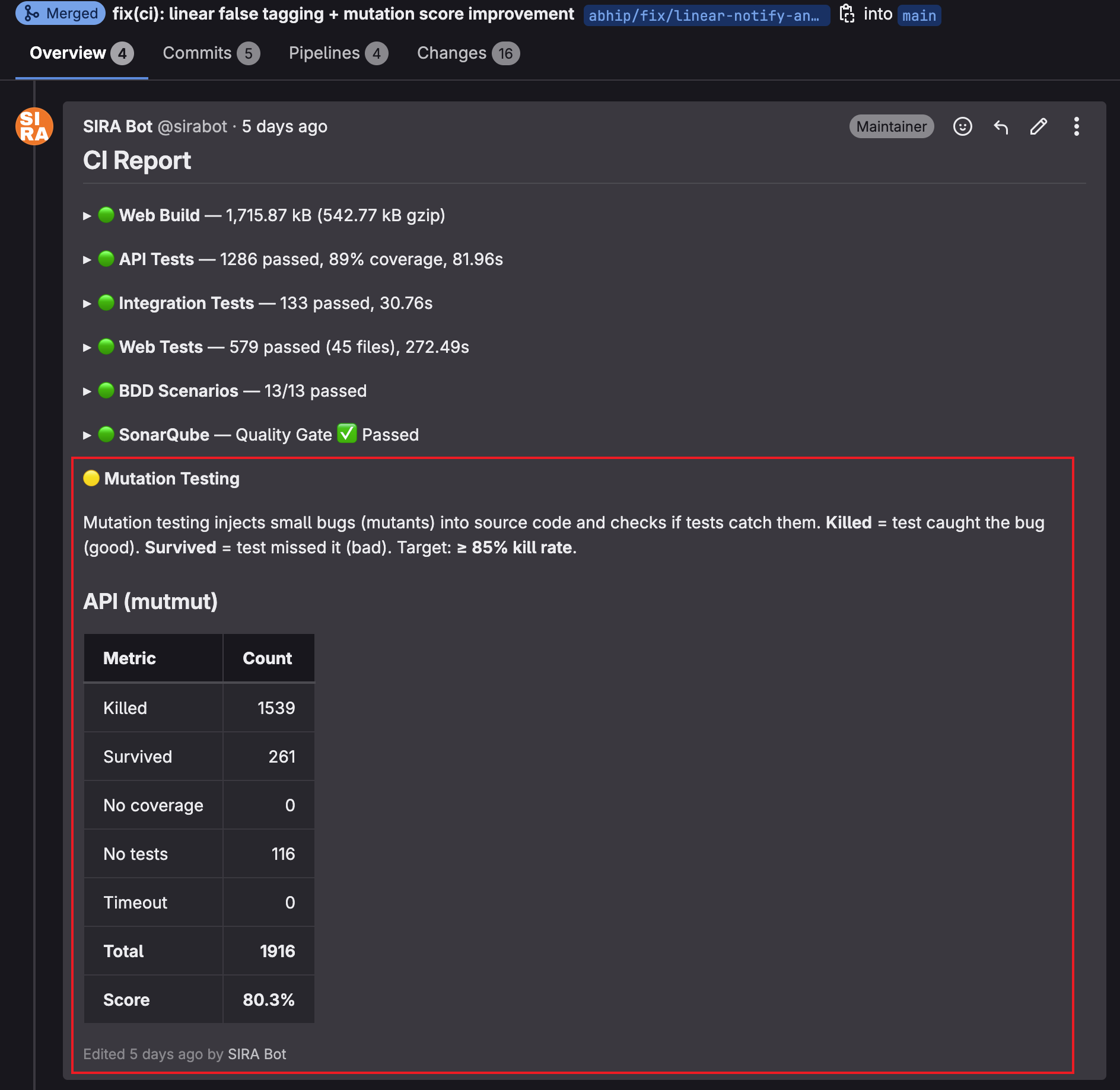
The progression across phases:
| Phase | New tests added | Cumulative mutation score (API) |
|---|---|---|
| Baseline (after config + CI wiring) | — | ~66% |
| Round 2 (broad-sweep survivor-killing) | ~200 | ~75% |
| Round 3 (per-method survivor targeting) | ~200 | 80.3% |
149 more mutants killed between the two snapshots; survived count dropped from 410 to 261; total (1916) unchanged because the source tree was identical. The only variable was test strength.
TypeScript via Stryker sits around 60%, meeting the low threshold but below high. The gap is inherent: src/lib/ has more React-component-adjacent code where mutation killing requires rendering-dependent assertions that Vitest only partially handles without heavier React Testing Library setup.
Technique 2: Input Space Partitioning via Property-Based Testing
Mutation testing optimizes assertion strength. Input Space Partitioning (ISP) optimizes input coverage. The formal definition from Ammann & Offutt (Chapter 6) divides the input domain into partitions such that any value in a partition is expected to produce the same behavior class, then requires at least one test per partition. The practical problem: humans are bad at enumerating partitions. We instinctively test happy-path inputs and miss boundary conditions, Unicode edge cases, empty containers, and numeric extremes.
Property-based testing is ISP made automatic. Instead of writing one test per input, you state a property (an invariant that must hold for all valid inputs) and let the tool generate hundreds of inputs drawn from strategies that systematically cover the partitions.
Tooling Choice
- Hypothesis for Python. De facto standard for property-based testing in the Python ecosystem.
- fast-check for TypeScript. Direct spiritual port of QuickCheck, native Vitest integration.
Both use the same underlying mental model: declare a strategy (generator) for each argument type, write a property as a function that must return true for any sampled input, and let the library handle input generation, shrinking on failure, and reproduction.
Example: Python Payment Invariants
A core business invariant: payment amount exceeding remaining invoice balance must always raise a ValueError, regardless of how close the excess is.
# apps/api/tests/test_property_payments.py
from hypothesis import given, settings
from hypothesis import strategies as st
positive_amounts = st.floats(min_value=0.01, max_value=1_000_000_000, allow_nan=False)
@given(
invoice_amount=positive_amounts,
overpay_fraction=st.floats(min_value=0.01, max_value=1.0, allow_nan=False),
)
@settings(max_examples=200)
async def test_overpayment_always_rejected(
invoice_amount: float,
overpay_fraction: float,
) -> None:
"""Payment exceeding remaining balance must raise ValueError."""
remaining = invoice_amount * 0.5
overpay_amount = remaining + (overpay_fraction * remaining)
with pytest.raises(ValueError):
await service.create(PaymentCreate(amount_paid=overpay_amount, ...))
Hypothesis samples 200 combinations of invoice_amount × overpay_fraction. The sampling strategy automatically hits partition boundaries: invoice amounts of 0.01 (minimum valid), near 1e9 (large), and values near the overpay edge (overpay_fraction = 0.01, just barely over). A hand-written test would likely pick invoice_amount=1000, overpay=500 once and call it done. Hypothesis exercises the partitioning axis systematically, and when a property fails, it shrinks the failing input to the minimal case that reproduces the bug.
Example: TypeScript Currency Formatter
The frontend uses fast-check to verify format invariants across 500 random inputs per property:
// apps/web/tests/lib/format.test.ts
import * as fc from 'fast-check'
import { formatCurrency } from '@/lib/format'
describe('formatCurrency — property-based tests', () => {
it('always contains "Rp" for IDR currency', () => {
fc.assert(
fc.property(
fc.double({ min: -1_000_000_000, max: 1_000_000_000, noNaN: true }),
(amount) => {
const result = formatCurrency(amount)
expect(result).toContain('Rp')
},
),
{ numRuns: 500 },
)
})
it('handles large numbers without throwing', () => {
fc.assert(
fc.property(
fc.double({ min: 1_000_000, max: 999_999_999_999, noNaN: true }),
(amount) => {
expect(() => formatCurrency(amount)).not.toThrow()
},
),
{ numRuns: 200 },
)
})
})
Three properties, 1200 cumulative sampled inputs per run, all verifying shape invariants that hand-written tests would enumerate once or twice each. The shrinking behavior matters in production: when formatCurrency once broke on a specific very-small negative double, fast-check shrank the failing input to -0.0000009 — a value no hand-written test would have imagined.
What Property-Based Testing Actually Caught
The test_days_late_is_always_payment_minus_due property caught a latent assumption early: the codebase originally treated days_late < 0 as an error condition rather than a valid “paid early” signal. Hypothesis sampled payment_date before due_date on its own, the property failed, and the shrinker reduced it to a one-day difference. The fix was to accept negative days_late as an early-payment indicator and adjust the downstream risk-scoring logic to handle it (not penalize the client).
This is the ISP promise made concrete: the partition “payment date strictly earlier than due date” was not explicitly tested by any hand-written example. The property-based framework sampled it automatically.
Scope and Limits
Property-based testing is not a replacement for example-based tests. It excels at:
- Pure functions with clear input/output contracts (formatters, parsers, calculators).
- Invariant preservation across transformations (encode/decode roundtrips, sort idempotence).
- Boundary exhaustion on numeric or string inputs.
It struggles with:
- Stateful flows where the valid input space depends on prior state. Hypothesis has a
@rule-based stateful extension but the mental overhead is high. We did not use it. - Side-effect-heavy code where the property is about what happened in the database, not what the function returned. Example-based integration tests win here.
In our codebase property-based tests are deliberately concentrated in two files per stack (test_property_payments.py, test_feature_engineering_unit.py for Python; format.test.ts, utils.test.ts for TypeScript). Spreading them everywhere would trade good signal for CI time with diminishing returns.
Technique 3: Branch Coverage as Control-Flow-Graph Proxy
Mutation testing and property-based testing both bound input behavior. Control-Flow-Graph (CFG) analysis (Ammann & Offutt, Chapter 7) bounds execution paths: every branch of every conditional should be exercised by at least one test. Line coverage misses this entirely — a test can cover every line of an if/else block by executing only one branch if both branches write to the same variable.
Implementing full CFG traversal requires symbolic execution tooling that most teams will never adopt. But the 80/20 proxy is branch coverage, which simply instruments the if/else / and/or / loop-exit-condition branches and checks that each has at least one test exercising it. Every mainstream coverage library can produce branch coverage; the trick is to enforce it with a CI quality gate rather than treating it as optional telemetry.
Configuration
The backend enables branch coverage via pytest-cov:
uv run pytest -n auto --cov=app --cov-branch --cov-report=xml:coverage.xml
The --cov-branch flag is the load-bearing part. Without it, coverage reports lines only. The -n auto runs tests in parallel across CPU cores.
The frontend emits branch coverage via Vitest:
pnpm test -- --coverage --coverage.reporter=lcov
Both coverage outputs are uploaded to SonarQube, which enforces the 85% new-code coverage threshold on every MR via a quality gate. A PR with insufficient branch coverage on newly written code cannot merge until the author adds tests for the uncovered branches.
The Gate Flow
flowchart TB
A([Developer opens MR]) --> B[CI runs tests
generates coverage.xml + lcov.info]
B --> C[Upload coverage to SonarQube
via sonar-scanner]
C --> D{Quality gate:
new_coverage ≥ 85%
new issues = 0
duplications ≤ 3%}
D -->|pass| E([Gate green
merge unblocked])
D -->|fail| F([Gate red
merge blocked])
F -->|author adds tests| B
The phrase new-code coverage is where the design pays off. Project-wide coverage is a lagging indicator (“we were at 85% last quarter, still at 85% this quarter”). New-code coverage is a leading indicator (“every PR must maintain the bar on the code it changes”). It prevents the classic regression where overall coverage stays stable because legacy code covers for uncovered new code.
Example: Caught by the Gate
A recent MR introduced a new Tiptap rich-text editor component. Initial CI run showed SonarQube new-code coverage at 28.5% (well below the 85% threshold). The gate failed, the MR could not merge, the author added a test file with branch-covering assertions for toolbar state, chip rendering, and link insertion. Coverage jumped to 97.7% on the same changeset. Gate passed. The feature shipped without the “I’ll write tests later” technical-debt accretion that plagues teams that treat coverage as advisory rather than enforced.
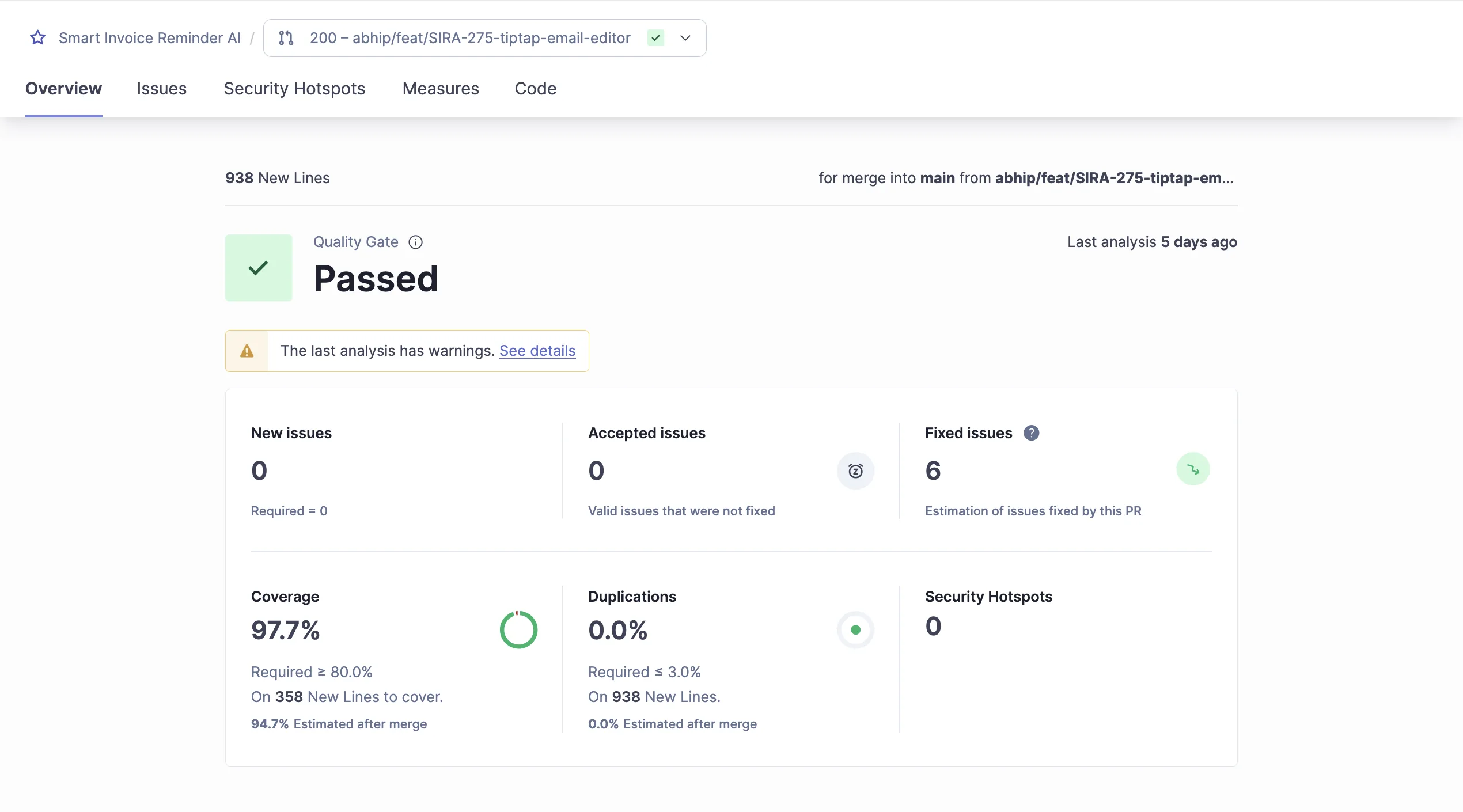
The dashboard makes the before/after a first-class project state, not a blog post claim. The three new-code conditions (coverage, issues, duplications) each show their actual value against the required threshold, and the gate’s single green check is what gates the merge. This is the concrete demonstration that branch coverage as a CI gate converts “best effort” into “required” without bureaucracy.
Why Branch, Not Just Line
A small example showing why line coverage is insufficient for CFG purposes:
def apply_discount(amount: float, is_vip: bool) -> float:
if is_vip:
amount *= 0.9
return amount
A single test calling apply_discount(100.0, True) gives 100% line coverage — every line in the function runs. But branch coverage shows is_vip == False is unexercised, and mutmut will promptly generate the if not is_vip: mutant which this single test cannot kill. Branch coverage requires two tests, one per branch, before the CFG is satisfied. Line coverage alone hides the second case.
This is why SonarQube’s gate is configured on new_coverage (which is branch coverage on changed lines), not on new_line_coverage (which would have accepted the one-test version above).
How the Three Techniques Compose
Each technique optimizes a different axis of test design. The composition matters more than any one of them alone:
| Axis | Optimizer | What “passing the gate” means |
|---|---|---|
| Assertion strength | Mutation score (mutmut, Stryker) | Wrong-but-structurally-valid implementations would be caught by the tests |
| Input coverage | Property-based testing (Hypothesis, fast-check) | Boundary and edge-case partitions are explored, not just the happy path |
| Control-flow coverage | Branch coverage via CI gate | Every if/else branch on newly written code is exercised by at least one test |
Mutation testing without branch coverage will find survivors in untaken branches but has no cheap way to systematize the fix. Branch coverage without mutation testing will green the gate on a test that covers both branches but asserts nothing substantive. Property-based testing is orthogonal to both; it works inside whatever coverage and assertion structure you already have, sampling more deeply within partitions you have identified.
The practical insight for our codebase: each technique is cheap to adopt but only if the others exist. Mutation testing on a codebase without integration tests produces noise (mutants survive against mocked DBs). Branch coverage without a quality gate is advisory and gets ignored. Property-based testing without a clear invariant vocabulary produces tests that pass trivially because the property is too weak.
What None of These Catch
A discipline worth practicing: being explicit about what a technique does not optimize. For each of the three above:
Mutation testing does not catch:
- Specification bugs (requirements were wrong; the code faithfully implements a broken spec).
- Concurrency bugs (mutants are syntactic; race conditions rarely map to a single mutation).
- Performance regressions (a mutant that halves throughput still passes the assertion suite).
Property-based testing does not catch:
- Stateful invariant violations across multi-step flows without
@rulestateful testing. - Properties you did not think to state. The framework samples inputs automatically but it does not invent invariants.
Branch coverage does not catch:
- Tests that execute both branches but assert nothing meaningful in either. This is why mutation testing is the complement.
- Path coverage (combinations of branches across multiple conditionals). Full path coverage is intractable for non-trivial programs; we accept this limit.
The combined approach gets you meaningfully closer to “my tests would catch a regression,” but the word “closer” is doing work. No test suite proves correctness; the best it can do is raise the cost of introducing a regression.
Reflection: Where the Effort Was Worth It, Where It Was Not
Worth it: Mutation testing on the services layer. The ratio of real bugs uncovered per hour of test writing was the highest of anything we did this sprint. Several classes of bug (silent None returns from mocked clients, off-by-one in date calculations, case-insensitivity assumptions) would have reached production without it.
Worth it: Branch-coverage-as-CI-gate. Free to implement once SonarQube is wired. The Tiptap editor MR is a clean example where the gate saved a code review cycle by catching missing tests at commit time rather than at human review.
Not worth it (yet): Stateful property-based testing. We tried it on the payment state machine (UNPAID → PARTIAL → PAID, plus CANCELLED transitions) and the overhead of defining the state model was higher than the bugs it caught. Example-based integration tests over the same transitions ended up cheaper per bug found. We may revisit this when the state space grows.
Not worth it: Chasing mutation score to 100%. The remaining ~20% on our backend is noise: logging-only mutations, defensive unreachable branches, configuration defaults. Killing them adds test fragility (asserting exact log strings) without catching real bugs. The diminishing returns curve is sharp around 80%, and that is where we stopped.
The meta-lesson is that test design optimization is not a single metric to maximize. It is a portfolio of techniques, each with a defined scope and known limits. Line coverage reports one number; it turns out to be the least informative of the four metrics (line, branch, mutation, property-violation-rate) a mature test suite should track. The industry has been optimizing the wrong variable for a while, and the tools to do better are freely available and well-integrated into the Python and TypeScript ecosystems. The hard part is not the tooling. It is deciding that “91% line coverage” is not an answer to the question the team thought it was asking.